
Harvester Settings
These settings control all aspects of harvesting metadata from your data source.
URI
The 'URI' is the location of the Data Source, from which XML documents are harvested by ARDC. Also known as the harvest point.
-
Any HTTP or HTTPS URL pointing to a RIF-CS XML feed for a DIRECT (HTTP) provider. Example: http://devl.ands.org.au/test/aims.xml.
-
For an OAI-PMH provider, the base URL of the Data Provider. Example: https://researchdata.edu.au/registry/services/oai
Harvest Method
The 'Harvest Method' specifies the means by which your metadata will be retrieved from the harvest point 'URI'.
-
GET Harvester: harvester connects directly to the Data Source URI using a HTTP Get and downloads XML in format specified in the Provider Type.
-
OAI-PMH Harvester: harvester connects to your OAI-PMH feed using the OAI-PMH protocol and downloads in format specified in the Provider Type. Includes the support for resumption tokens in the case of large harvests, and error and exception reporting.
-
CSW Harvester: (Custom method) harvester connects to a Catalog Service for the Web (CSW) instance and downloads XML in format specified in the Provider Type.
-
CKAN Harvester: (Custom method) harvester connects to CKAN instance and downloads JSON in format specified in the Provider Type.
-
CKANQUERY Harvester: (Custom method) harvester requests JSON metadata from CKAN API using the provided URL. Note that you do not need to add the "start" and "rows" parameters to your URL as these are automatically set by the harvester.
-
JSONLD Harvester: (Custom method) A sitemap crawler that extracts JSON-LD content. Requires a URL pointing to a sitemap file, it can be text or xml (either <sitemapindex> or <urlset>). A default crosswalk from JSON-LD to RIF-CS will be run on import. This can be overwritten by adding your own crosswalk to the harvest settings.
-
MAGDAQUERY Harvester: (Custom method) harvester requests JSON metadata from MAGDA Search API using the provided URL. Note that you do not need to add the "start" and "limit" parameters to your URL as these are automatically set by the harvester.
-
PURE Harvester: (Custom method) a simple dataset harvester using the Elsevier Pure API
-
ARCQUERY Harvester: (Custom method) retrieves all records from the Australian Research Council Data Portal API
-
OPEN DATA API Harvester: (Custom method) harvest method to support harvesting from APIs that implement the US Government Project Open Data API.
-
Dynamically inserted JSONLD Harvester: (Custom method) A sitemap crawler that extracts dynamically injected JSON-LD content. Requires a URL pointing to a sitemap file, it can be text or xml (either <sitemapindex> or <urlset>). A default crosswalk from JSON-LD to RIF-CS will be run on import. This can be overwritten by adding your own crosswalk to the harvest settings.
-
FIGSHARE2 Harvester: (Custom method) harvester requests JSON metadata from Figshare RESTful API Version 2.
Please note that custom harvest methods require additional configuration to take place before they can be used.
All JSON responses are converted to serialised XML before any crosswalks are applied.
Additional harvest methods can also be supported. For more information please contact services@ardc.edu.au
OAI-PMH Harvester
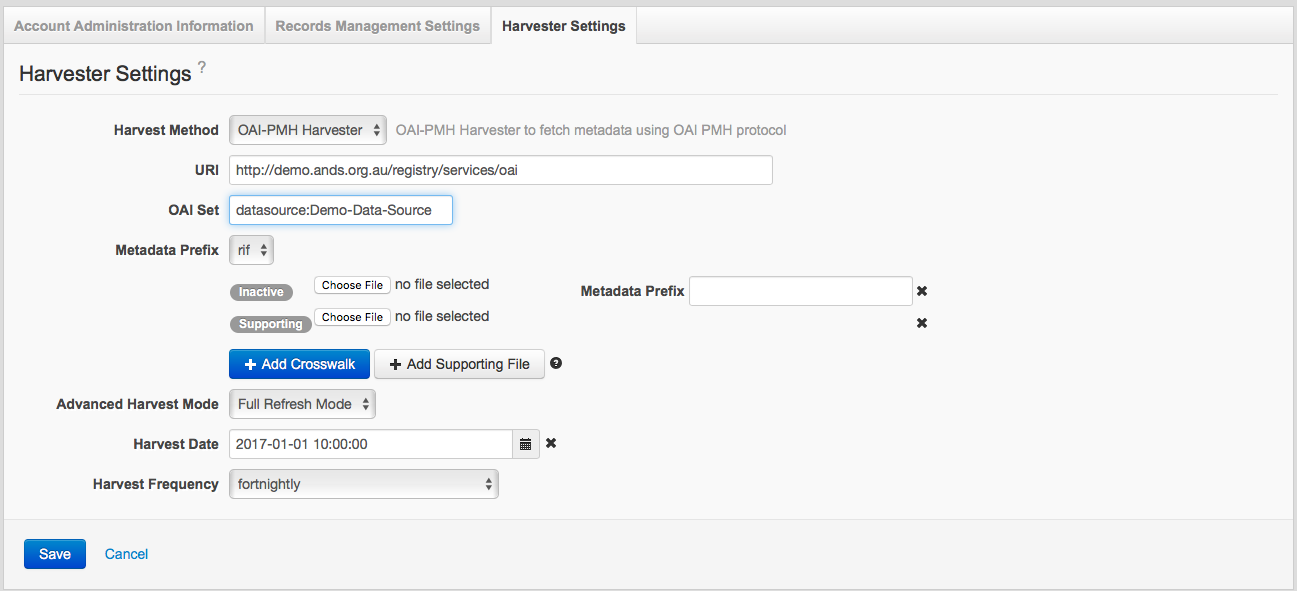
Sample OAI-PMH harvester settings
Troubleshooting: Make sure you don't accidentally specify leading or trailing spaces when you enter your harvest URI-this is one of the causes of harvests failing.
OAI Set
The 'OAI Set' field is available with a 'Harvest Method' of OAI-PMH. It allows you to instruct the ARDC harvester to retrieve records from a specific set in your OAI-PMH feed. This is especially useful when you only wish ARDC to harvest a subset of the records available through your OAI-PMH instance.
Metadata Prefix
The 'Metadata Prefix' drop down is available with a 'Harvest Method' of OAI-PMH. The drop down allows you to tell the harvester what metadata prefix should be requested from your OAI-PMH service. ‘rif’ (i.e. RIF-CS) is the default value. Additional prefixes can be added to your data source by using the ‘Add Crosswalk’ button, however if the format of the data is not RIF-CS a crosswalk will need to be uploaded.
To specify a crosswalk and add supporting files, please see Add Crosswalk and Supporting File section below.
CSW Harvester
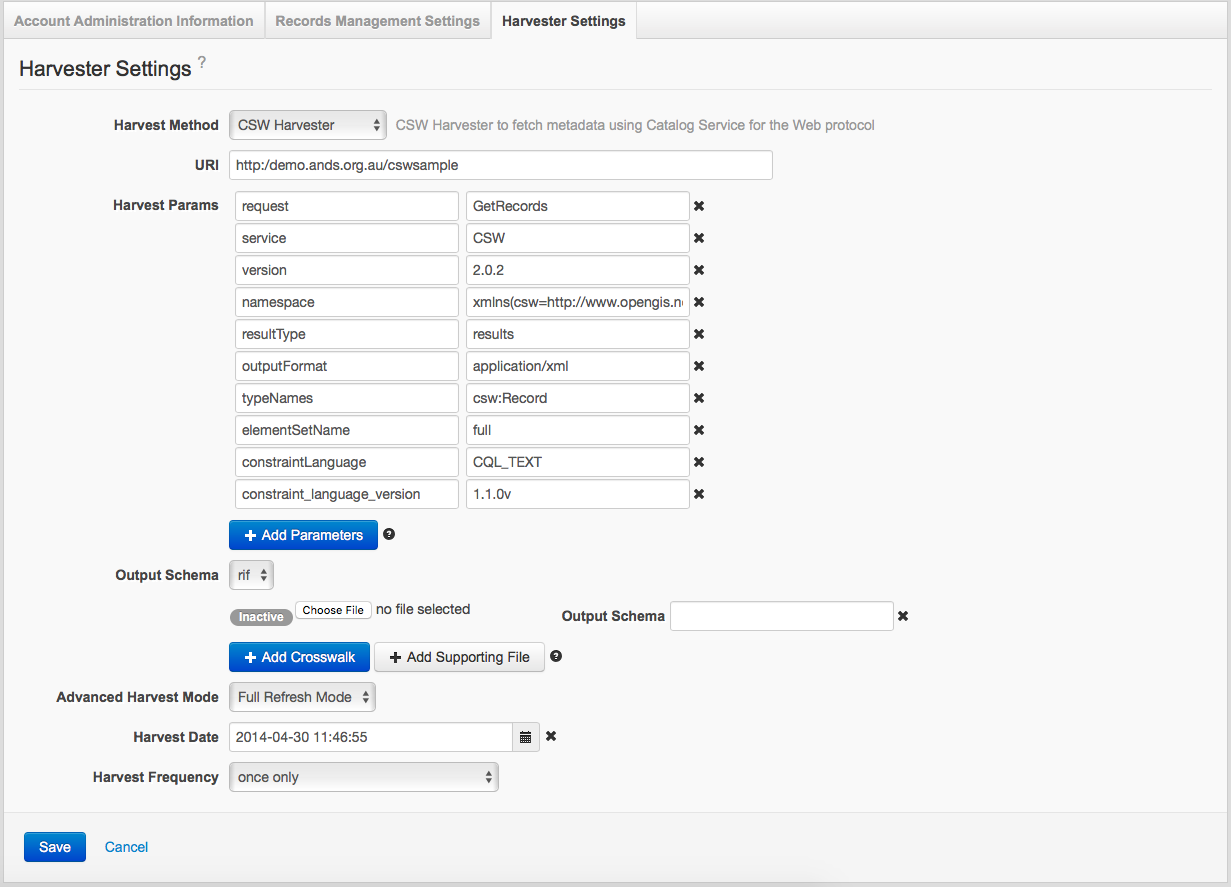
Sample CSW harvester settings
Harvest Params for the CSW Harvester
The 'Harvest Params' fields are displayed where a 'Harvest Method' of 'CSW Harvester' is selected. The fields are displayed as Name-Value pairs, and allow you to customise the parameters passed in a CSW harvest request.
By default the system provides the minimum set of CSW parameters required. You may change the value for these default parameters but should not delete them. If removed the system will automatically reinsert them with the default value upon save. To add additional parameters to the request, simply click the 'Add Parameters' button displayed at the bottom of the table and enter the parameter name and value in the added fields.
Output Schema for the CSW Harvester
The 'Output Schema' drop down is available with a 'Harvest Method' of CSW. The drop down allows you to specify the ‘outputSchema’ parameter which is required by CSW service requests. The parameter specifies the return format for the CSW request and must be set to the URI of the output metadata schema (e.g. http://www.isotc211.org/2005/gmd).
To specify a crosswalk and add supporting files, please see Add Crosswalk and Supporting File section below.
FIGSHARE2 Harvester
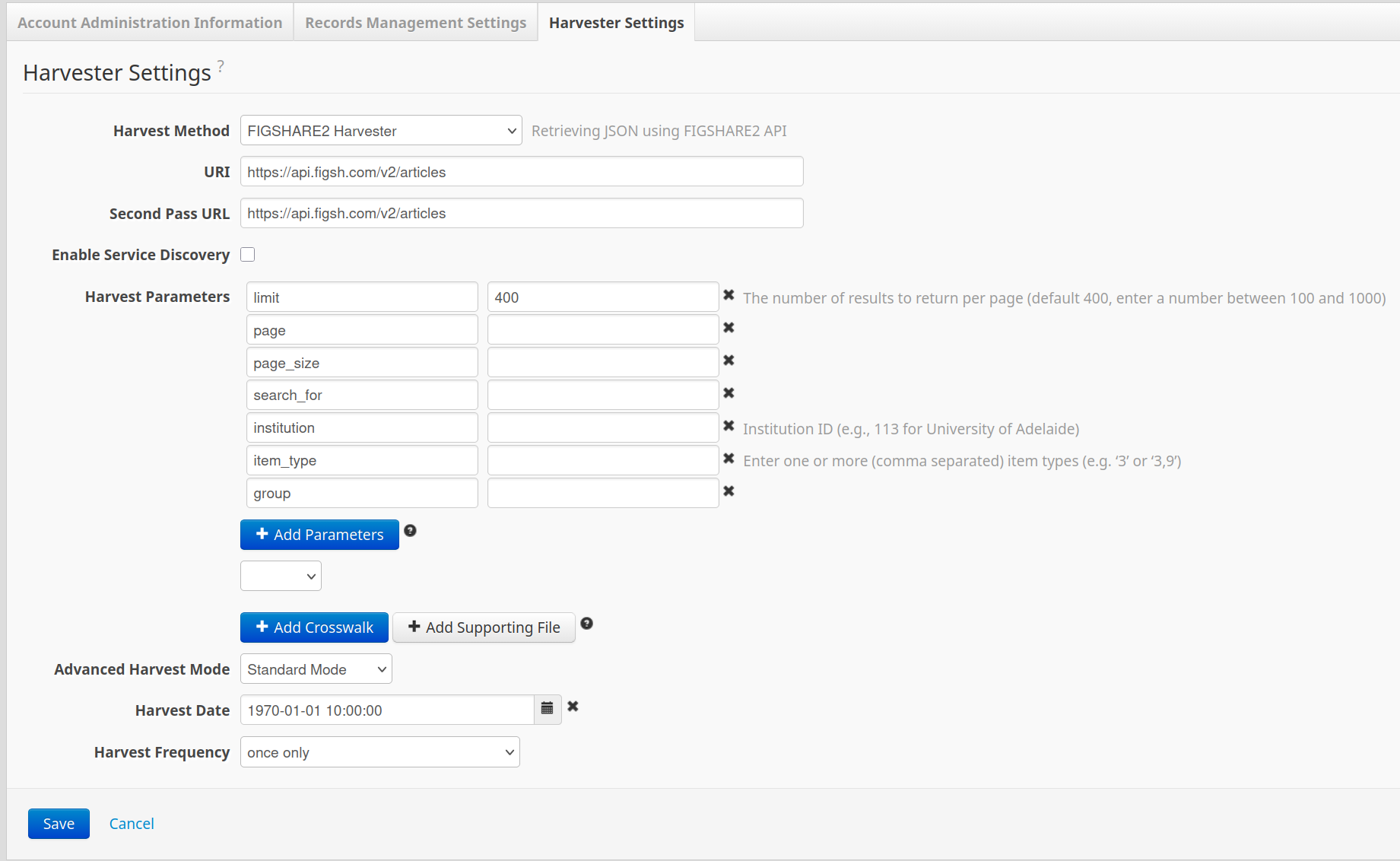
Sample FIGSHARE2 harvester settings
Harvest Params for the FIGSHARE2 Harvester
The 'Harvest Params' fields are displayed where a 'Harvest Method' of 'FIGSHARE2 Harvester' is selected. The fields are displayed as Name-Value pairs, and allow you to customise the parameters passed in a FIGSHARE2 harvest request.
By default the system provides a number of Figshare RESTful API parameters, but only provides a value for one of them. The minimum recommended parameters are “institution”, “item_type”, and “group”. Values are required for each of these recommended parameters, and they should not be deleted. To add additional parameters to the request, simply click the 'Add Parameters' button displayed at the bottom of the table and enter the parameter name and value in the added fields.
To specify a crosswalk and add supporting files, please see Add Crosswalk and Supporting File section below.
All other harvest methods
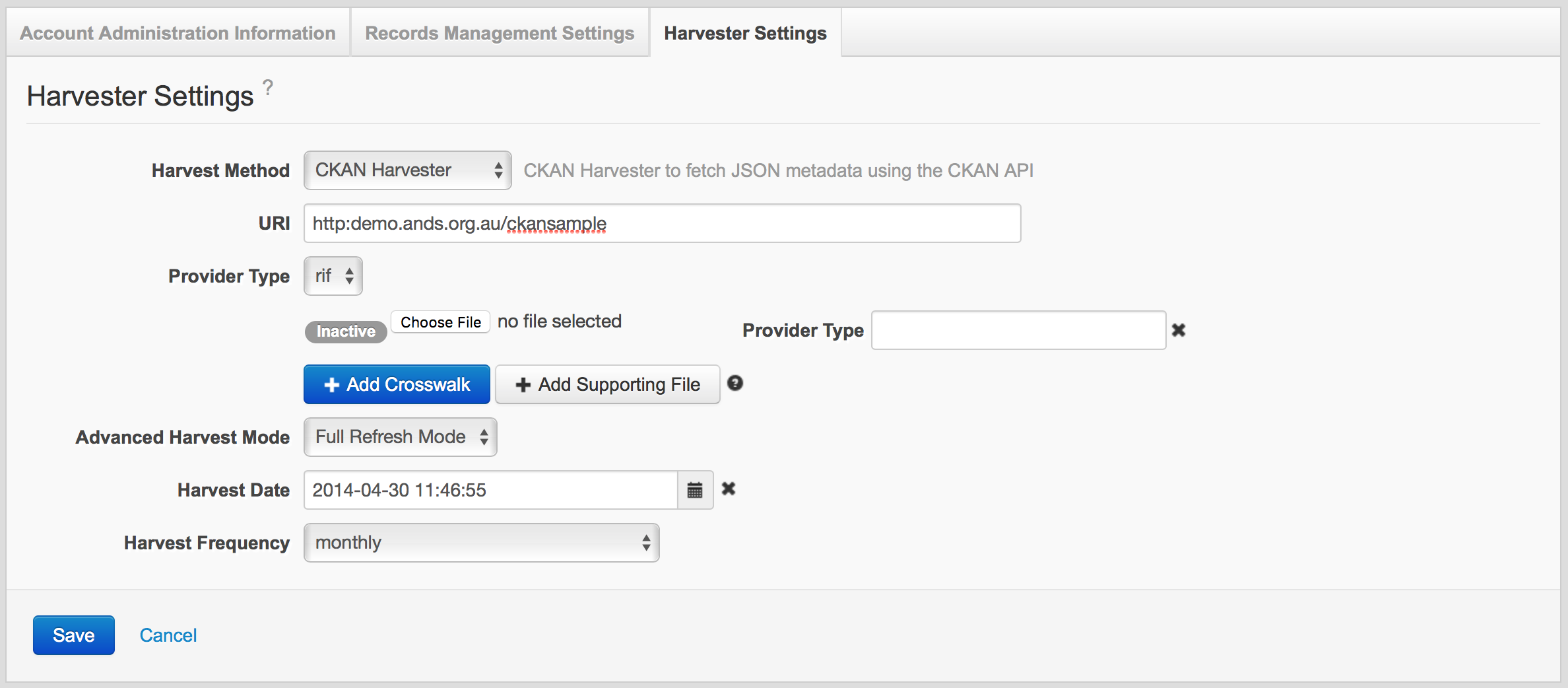
Sample CKAN harvester settings
Provider Type
The 'Provider Type' value describes the kind of metadata document you are making available for harvest and is used to identify a matching crosswalk in your Data Source. ‘rif’ (i.e. RIF-CS) is the default value. Other provider types (e.g. Dublin Core, ISO19139, CSV ,etc) can configured for your data source by adding a crosswalk from the type to RIF-CS.
To specify a crosswalk and add supporting files, please see Add Crosswalk and Supporting File section below.
Add Crosswalk & Supporting File
-
The
'Add Crosswalk'button allows users to upload an XLST crosswalk and configure it to be run during a harvest. Multiple crosswalks can be uploaded but each needs to be uniquely identified by specifying a Crosswalk Provider Type, Output Format or Metadata Prefix. Once uploaded and identified the crosswalk will be available for selection from the Provider Type, Output Format or Metadata Prefix drop down (dependent on harvest configuration). When selected, a green 'active' label will display next to the crosswalk. -
The
'Add Supporting File'button can be used to upload a supporting file which can be referenced and used from within an XSLT crosswalk. Supporting files must be in a format XML or XSL
Visit the Crosswalks: Transform your metadata page on the ARDC website for the list of available crosswalks to RIF-CS (e.g. ISO19115, CKAN, Dublin Core, etc.)
Advanced Harvest Mode
One of three harvest modes can be selected for ingesting records, these modes are as follows:
-
Standard Mode: Standard mode will ingest all records from the data source feed (Standard is the default mode)
-
Incremental Mode: The Incremental Mode will use OAI-PMH to support harvesting on a
"from and until"basis. This means that only records that have been created or modified "from" the last harvest date, "until" the date of the new harvest will be included within the Record providers existing dataset.
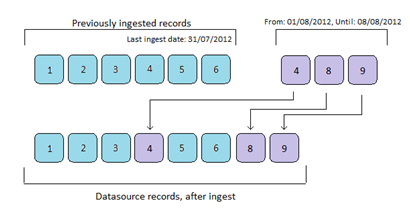
The above example shows that after ingest record 8 & 9 will be included into the data source, while the original record 4 will be replaced with the newly ingested record 4.This mode will only function if the harvest method is set to "OAI-PMH Harvester", and if the OAI-PMH provider correctly supports the "from and until" parameters as per the OAI-PMH Specification.
-
Full Refresh Mode: The Full Refresh Mode will remove all previously harvested records and update the dataset with the latest ingested records. Records created manually using the Add Registry Object screens will not be removed when using this harvest mode.
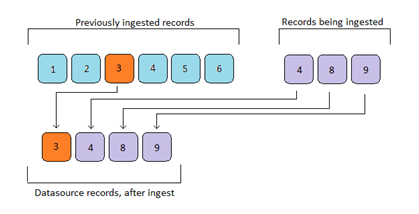
The above example shows that records 1, 2, 5 & 6 are removed, new records 8 & 9 are placed in the data source and record 4 is replaced. Also record 3 was not removed as it was manually created using the Registry Add Registry Object screen.
Harvest Date
Use the 'Harvest Date' field to specify a future date and time when a harvest will occur or when regular reoccurring harvests begin. The calendar widget allows nomination of a time zone.
Harvest Frequency
Use the 'Harvest Frequency' drop down to specify the frequency for your harvest.
More information
-
Crosswalks: Transform your metadata page on the ARDC website