
Beyond RIF-CS: Metadata for Services Good Practice Guide
Introduction
Data services in the research domain support the use of research collections and datasets by providing automated functions for the creation, access, processing and analysis of data. More and more data providers are publishing their data through services. In Australia, for example, research organisations, science agencies, government departments and a number of national research infrastructure facilities are all moving to more formal publishing of data through services. Also, data consumers are increasingly accessing data services and connecting them with other services or tools (e.g. virtual laboratories) for data analysis, processing and visualisation.
Context
In 2017-18, the Australian Research Data Commons (ARDC) convened a Data Services Interest Group around data service provision and consumption across the NCRIS facilities, science agencies, universities, and broader public sector. To improve discovery and use of data and related services across these organisations, the Interest Group agreed on some “end user” scenarios that the group aspired to support:
Individual researchers looking to “plug data into” their own tool or model using standard services
Virtual laboratories providing tools over data from various common data services
Third party innovators leveraging data across a pool of services for development work.
The Interest Group set out to identify “shared practice” for exposing information about data and related services across all organisations by asking:
What information set would a data steward need to possess to satisfy the requests in those scenarios?
In current information technology practice where might such information typically be stored and exposed in data management systems?
Core metadata for services and related collections
The Interest Group looked at Data and related Service metadata terms from a number of metadata schemas, and attempted to group these terms by concept in Data and Data-Service Metadata Concepts and Schemas (Google Sheet): each row is a group of terms from various schemes; the groups are named in column B, ‘Concepts - for data and related services’.
Based on this, the Interest Group agreed upon a core information set for “data and related services” which might then be encoded in a given standard and exchanged using the corresponding protocol. The set has been tested against common OGC/W3C/OpenAPI/Web-index standards to make sure it works within a given metadata-protocol combination (eg ISO 19115 and CSW). However, it does not prescribe a particular metadata scheme, exchange protocol, or information management approach. Further detailed information on this approach is available in the document, Data and related Services: discovery and use (Google Document).
The agreed core set of information for data and related services follows:
(Essential = information required to respond to the three end-user scenarios listed above; more details here;
Recommended = desirable information for discovery, appraisal, citation, re-use, etc)
| Concepts, for data-services and related data | Requirement |
|---|---|
service URL service identifier (if different from the URL) | Essential * |
service type: protocol and version - e.g. ‘wms 1.3’ service-use documentation (if protocol is non-standard - e.g. URL to service description) service type: function (if protocol is non-standard - e.g. ‘download’) | Essential* |
service type: resource type (e.g. ‘service’) | Essential |
data subject (e.g. 'observedProperty', 'variableMeasured') | Essential |
service title | Essential |
data spatial coverage | Essential if available |
data geographic/projected CRS | Essential if available |
data temporal coverage | Essential if available |
service description/ abstract | Recommended |
data format | Recommended |
service date (modified) | Recommended |
service rights | Recommended |
data rights | Recommended |
data contributor/owner/publisher | Recommended |
data language | Recommended |
service language | Recommended |
data identifying information - its text name, or an identifier such as a uuid or doi to a landing page | Recommended |
service contributor/owner/publisher | Recommended |
* = essential for a minimum response
Community standards for the mapping of these concepts (in development):
Examples of service description using the agreed core concepts
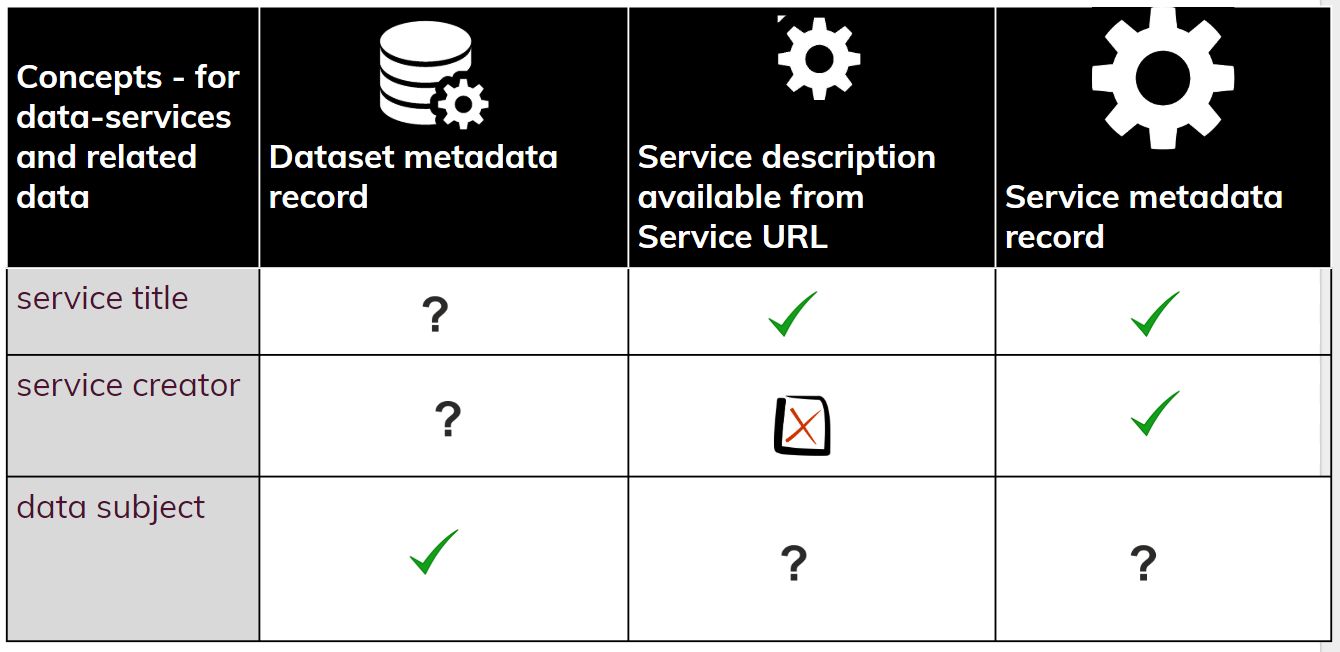
There is no assumption that data provision organisations necessarily maintain independent metadata descriptions of services; there is however a shared expectation that a core set of information about data and related services be available from somewhere in the data management system. These might include: references to services within dataset records; or “self-describing” interfaces such as GetCapabilities; or combinations of both (see Data and related Services - Metadata Views for more information). The image below demonstrates how information about the three core concepts: "service title", "service creator" and "data subject" could be obtained from various locations in the data management system.
Following are three real-life examples from some of the data provision organisations we have been working with:
Service record from the GA metadata catalogue:
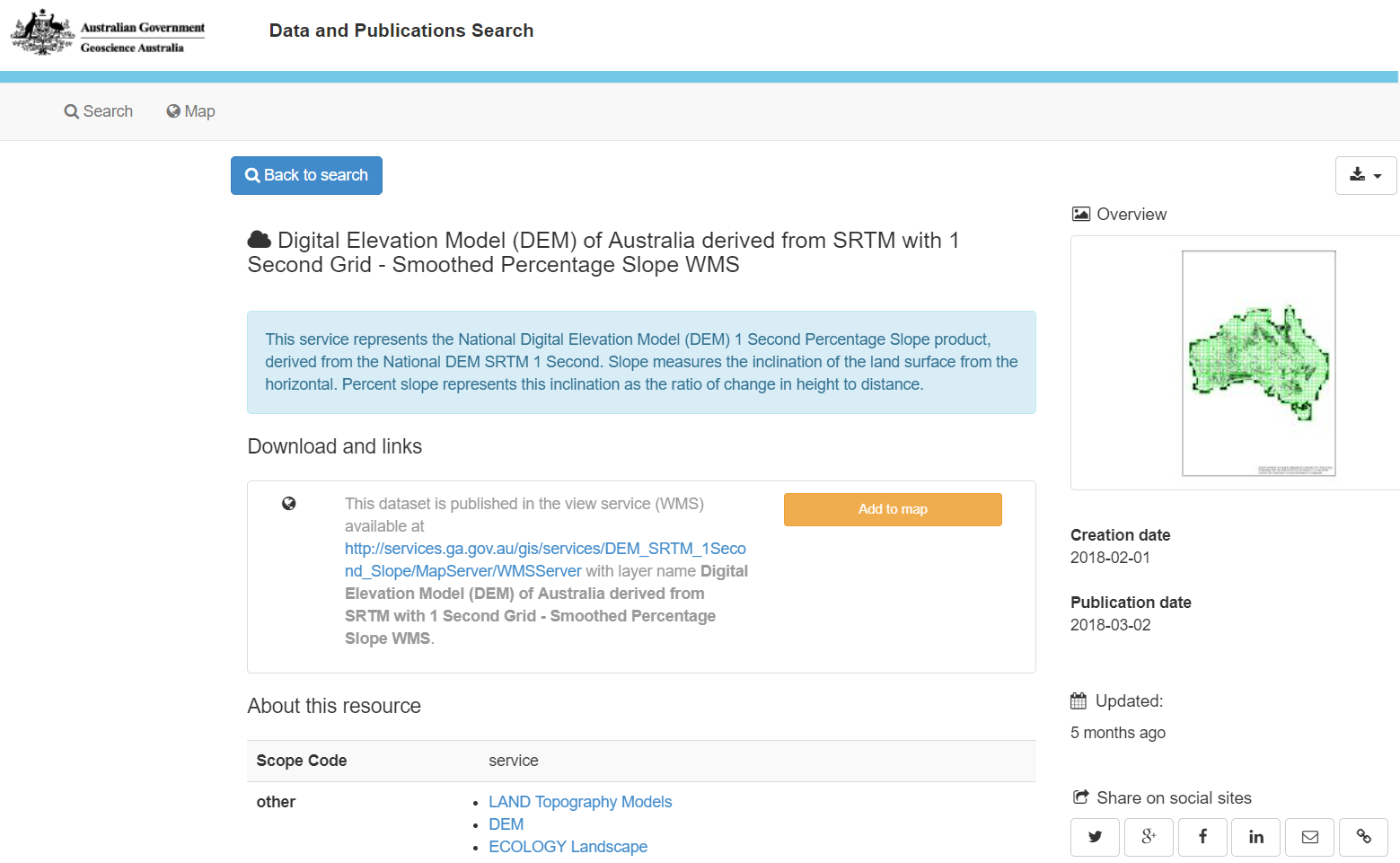
Service metadata extracted from the above and mapped to the core service concepts:
| Service concept | Value |
|---|---|
service URL | http://services.ga.gov.au/gis/services/DEM_SRTM_1Second_Slope/MapServer/WMSServer |
service type: protocol and version | Protocol: WMS 1.3.0, 1.1.1 |
service type: resource type | service |
data subject | Land topography models, Ecology landscape, elevation, slope |
service title | Digital Elevation Model (DEM) of Australia derived from SRTM with 1 Second Grid - Smoothed Percentage Slope WMS |
data spatial coverage | ["112.000000 -44.000000,154.000000 -44.000000,154.000000 -9.000000,112.000000 -9.000000,112.000000 -44.000000"] |
data geographic/projected CRS | |
data temporal coverage | |
service description/ abstract | Digital Elevation Model (DEM) of Australia derived from SRTM with 1 Second Grid - Smoothed Percentage Slope WMS |
data format | |
service date (modified) | 2018-06-18 |
service rights | |
data rights | |
data contributor/owner/publisher | Geoscience Australia |
data language | |
service language | |
data identifying information | UUID: aac46307-fce8-449d-e044-00144fdd4fa6 |
service contributor/owner/publisher | Geoscience Australia |
IMAS UTAS dataset record in the AODN portal:

Hyperlink to Service URL within dataset record:

Service description at Service URL (OGC WFS):
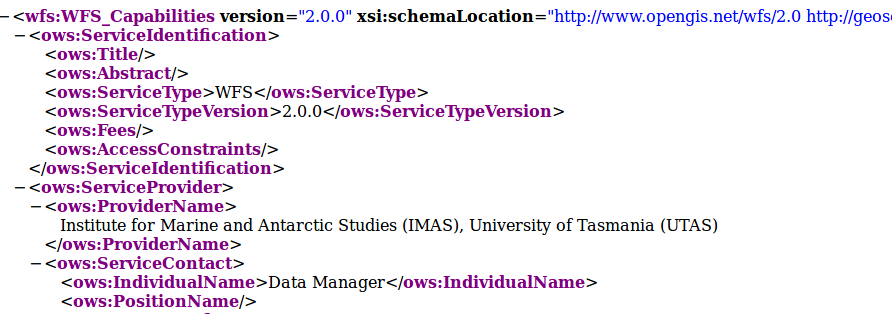
Summation of service metadata extracted from the above and mapped to the core service concepts:
Service concept | Value |
|---|---|
service URL | |
service type: protocol and version service type: function | Protocol: WFSFunction: Access |
service type: resource type | service |
data subject | bathymetry/seafloor topography... |
service title | seamap |
data spatial coverage | -27.64400, 149.28540, 154.29516, -37.60255 |
data geographic/projected CRS | |
data temporal coverage | 2002-05-30 |
service description/ abstract | |
data format | SHAPE-ZIP |
service date (modified) | |
service rights | |
data rights | CC-BY 4.0 |
data contributor/owner/publisher | IMAS UTAS |
data language | English |
service language | English |
data identifying information | ID: 9a94d1ba-8509-4d78-8b55-d25fd222cdffName: MAP - NSW marine habitats |
service contributor/owner/publisher | IMAS UTAS |
Service OpenAPI URL - description for multiple service endpoints provided in json:
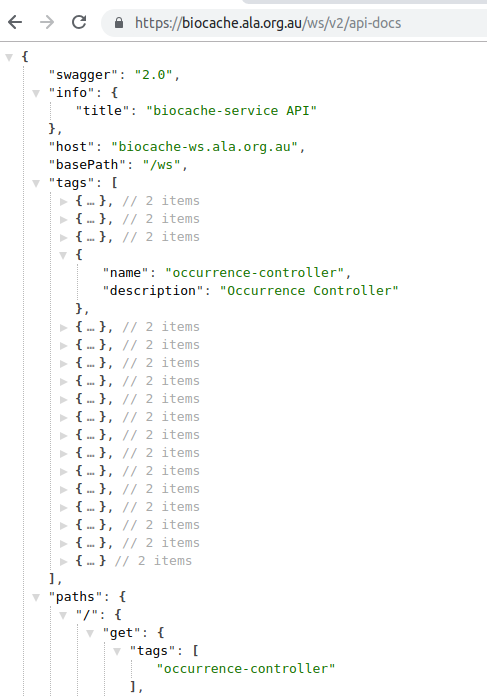
Summation of service metadata extracted from the above and mapped to the core service concepts:
Service concept | Value |
|---|---|
service URL | |
service type: protocol and version | webservice Parameters: |
service type: resource type | service |
data subject | occurrence |
service title | occurrenceSearchUsingGET |
data spatial coverage | |
data geographic/projected CRS | |
data temporal coverage | |
service description/ abstract | occurrenceSearchUsingGET operation available at biocache-service API |
data format | json |
service date (modified) | |
service rights | |
data rights | |
data contributor/owner/publisher | |
data language | |
service language | |
data identifying information | |
service contributor/owner/publisher | Atlas of Living Australia |